Bilişim okutulan okullarda yıllardır, ilişkisel veri modeli ve RDMS (Relational Database Management System) programlar okutuluyor. Bunlardan en popülerleri Açık Kaynak tarafında, MySQL, diğer tarafta MS SQL server ve Kurumsal alanlarda da Oracle.
PostgreSQL, ülkemiz için pek popüler olmasa da bilhassa Python programcıları başta olmak üzere dünyada saygın yeri olan bir başka RDMS. Ülkemizdeki Oracle müptelaları için şunu da hemen belirteyim ki, Ortacle 7 den itibaren kullanılan “snapshot isolation” kavramı PostgreSQL’den alınmıştır. (Kaynak: PostgreSQL 9 Administration Cookbook )
Ancak ne var ki son bir kaç yıldır NoSQL (Not Only SQL) kavramı ortalığı kasıp kavurdu. Kavram yeni değildi ama hiç bu kadar popüler olmamıştı.
Bu yaklaşımda popüler olan Veri Tabanı teknolojileri ise MongoDB, CouchDB.
Bu yeni trend ile de başarılı olan projelerin yanında pek çok proje başarısız oldu. Çünkü her yerde kullanılabilecek cinsten bir model değildi. Kıssadan hisse, hiç bir teknoloji tek başına her derde deva değildir.
PostgreSQL , NoSQL’in yakaladığı bu akımı yönetebilmek adına ve JSON veri tipini ekledi. Ayrıca çok karmaşık olmamak kaydıyla JSON içerisinde sorgulamalar yapabileceğimiz SQL cümleleri geliştirdi. Böylelikle şimdi anlatacağımız Veri Tabanı modeli çözümüne ortak olmuş oldu.ve MongoDB 3.2 versiyonunda Windows ve Mac için PostgreSQL sürücülerini kullanacağını duyurdu
PostgreSQL’in MongoDB karşısındaki performansına baktığımızda:
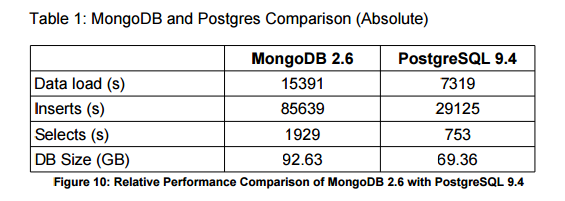
Postgresql ve MongoDB performans karşılaştırma tablosu
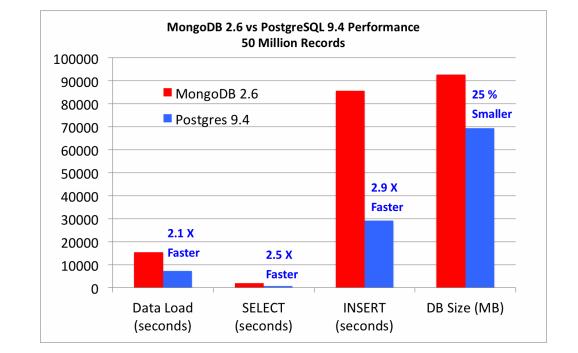
Postgresql ve MongoDB performans karşılaştırma grafiği
Bunu neden yaptığını anlamak daha kolay olabilir. Elbette özellikle arşivleme ve yedekleme konusunda İlişkisel olmayan veri tabanı yönetim sistemlerinin avantajı büyük. 100GB lık bir ilişkisel veri tabanını yedeklemek saatler sürebilir. Üstelik web ortamları gibi canlı veri ortamlarında, verinin anlık değişebildiğini de göz önünde bulundurmalıyız.
NE ZAMAN NoSQL?
Peki o zaman ne yapmalıyız? Ne zaman ilişkisel, ne zaman İlişkisel olmayan veri tabanı kullanmalıyız?
Web ortamlarında istatistiksel verilere kaynaklık eden veriler vardır. Yazımın bundan sonrası için e-ticaret sitesi örneğini kullanacağım. Bir e-ticaret sitesinde Bir milyon ürün olabilir. Bu ürünlerin her birinin detay sayfası vardır. Bu detay sayfalarına ziyaretçiler, tıklar. Her bir tıklama kayıt altına alınmalıdır. Bu tıklamaların bazıları, kimliği belli tıklamalardır. Yani sitenin üyesi olan, oturum açmış müşterilerin tıklamalarıdır.
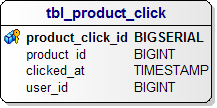
Ürün tablosu PostgreSQL ER Diagramı
Böyle bir tabloda milyonlarca kayıt bulunur ama hiç birisi tek başına bir anlam ifade etmez. Ancak bir araya geldiklerinde bazı soruların yanıtı olurlar:
- X ürününe kaç kişi bakmış?
- Bir üye X ürününü farklı zamanlarda kaç kez incelemiş?
- En çok hangi ürünler ziyaret edilmiş?
- X ürününü ziyaret edenler başka hangi ürünleri en çok ziyaret etmiş? Buradan ürün önerileri de çıkar. Bu ürünü inceleyenler şu ürüne de baktılar gibi.
Görüldüğü üzere bu tablodaki verilerin kullanılabilmesi için bir işleme tabi tutulmaları gerekir. Devasa büyüklükte olacağı tahmin edilebilen bu tablo ilişkisel yapıda olduğunda veri tabanını da şişirecektir! Bu tablonun ilişkisel bir veri tabanında olmasına gerek yoktur. Ancak işlem sonrasında ortaya çıkan rakamlar ilişkisel veri tabanına yazılabilir. Her iki mimariyi birlikte kullanan başarılı pek çok proje vardır.
İlişkisel olmayan veri tabanı yapısındaki bir diğer avantaj ise esnekliktir. E-Ticaret sitesinde ürünlerin her biri farklı öz niteliklere sahiptir. Bir dizüstü bilgisayarın hafıza, işlemci, ekran büyüklüğü gibi özellikleri var iken bir televizyonun ekran büyüklüğü, oynatabildiği video formatları gibi özellikler olabilir. Ürün özelliklerini ilişkisel veri tabanında şu şekilde modelleyebiliriz:
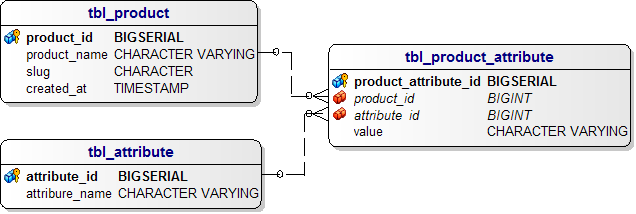
Ürün ve Ürün Özellikleri Tabloları için İlişkisel ER Diagram
Ancak bir sorunumuz var!
bir milyon ürünü olan bu e-ticaret sitesinde böye bir ilişki kurmak veri tabanı yönetim sistemini mahfedecektir. Çünkü bu iş için yapılacak JOIN sırasında devasa üç tablonun dosyaları birlikte hafızaya çoğu zaman birden fazla kez yüklenmek istenecektir. Tasarladığımız yapının maliyeti çok yüksek oldu!
Aklımıza ilk gelen çözüm ilişkisel olmayan mantıkla modelleme yapmak olabilir, Ama ürünlerin marka ve kategori ile de ilişkileri olduğundan, bize daha çok sorgu dışı kod yazmamız gerekecektir. Usta geliştiriciler bilir ki veri tabanından sadece ihtiyacımız kadar veriyi, mümkün olduğu kadar az seferde (mümkünse tek seferde) çekmek gerekir.
HİBRİT DATA MODEL
Hibrit data Model bu gibi durumlar için kullanılabilecek bir çözümdür. İlişkisel veri tabanında ilişkisel olmayan verileri tutmaya yarar. Yukarıdaki ürün tablosunu hibrit data modeli şu şekilde olabilir:
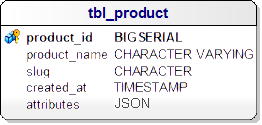
Ürün Özelliklerinin, Ürün tablosunda, JSON formatta modelleyen ER Diagram
attributes alanı, ürüne göre farklılık gösterebilecek esneklite bir JSON nesenesi haline geldi, Ancak hepimiz biliyoruz ki e-ticaret sitelerinin olmazsa olması filtreleme mekanizmasında ürünler özelliklerine göre filtreleme yapılır. Bu durumda attributes alanında nasıl sorgulama yapacağız?
Bu sorunun cevabını da hemen bir örnekle cevaplandıralım.
ürünün attributes alanı şöyle olsun:
{
screen_size: '15.4',
cpu_family: 'i7',
ram:8,
ram_unit: 'GB'
cpu_model: '5500U',
storage_type: 'SSD',
storage_capacity: 250,
storage_capacity_unit: 'GB'
}
Bu tabloda “i7” işlemcili ürünleri bulmak istersek SQL sorgumuzu da şöyle oluşturmamız gerekir:
select * from tbl_product where (attributes->>'cpu_family')::text = 'i7';
Ya da Ram’i 4 GB ‘den büyük ürünleri istersek:
select * from tbl_product where (attributes->>'ram')::int > 4;
->> operatörü bir nesne içerisindeki property’i ifade eder. Eğer -> şeklinde kullanılırsa nesne içindeki nesne yada diziyi ifade edecektir. PostgreSQL’deki diğer JSON sorgulama ifadelerini buradan inceleyebilirsiniz.
KISITLAMALAR
gönül isterdi ki bir güncellemeyi şu şekilde basitçe yapabilelim:
update tbl_product set (attributes->'ram')::int = 15 WHERE proudct_id = 1;
Ama bu yanlış. PostgreSQL’de JSON alanların tamamı güncellenmek zorundadır. Yani bu işlemin doğrusu şu şekilde olmalı:
update tbl_product set attributes = '{
screen_size: "15.4",
cpu_family: "i7",
ram:8,
ram_unit: "GB"
cpu_model: "5500U",
storage_type: "SSD",
storage_capacity: 250,
storage_capacity_unit: "GB"
}'::json where product_id = 1;
Daha gelişmiş JSON sorgularına yazının ikinci bölümü olan: “Hybrit Data Model 2. Bölüm: PostgreSQL’de JSON sorguları” başlıklı yazıda okuyabilirsiniz.
1 comment for “SQL ve NoSQL modelleme, Hibrit Data Model”